








僕はこれまで画像生成AIや動画生成AIというものにほとんど触れることがない生活を送ってきました。
しかし、ある日ふと観た動画から流れた音楽をきっかけに、ほぼ知識ゼロの状態から各種生成AIを利用することで1ヵ月でアニメOP風の動画(約1分40秒)を完成させることができました。
 うーすけ
うーすけ以下が、実際に僕が作成した動画です。
観ていただけると嬉しいです!
今回は、自分自身の記録のため、そしてこれから動画制作に挑戦してみたいと考えている人のために、動画制作に至ったきっかけや実際の動画制作プロセスを振り返っていきます。
生成AIを利用すれば時間もお金もかけずに作れてしまう、なんていう簡単なものでは決してありません。
ただ、しっかりとひとつひとつステップを踏んでいけば、きっと誰にでも制作できると思います。
これから生成AIを利用した創作活動に踏み出そうとされている人の参考になれば幸いです。
きっかけ:Sunoとの出会いと楽曲制作
そもそもなぜ生成AI動画を制作しようと思ったのか、そのきっかけはたまたまYouTubeで観ていた動画で流れた音楽です。
最初は、普通に人が作って人が歌っているものだと思っていました。
しかし、どうもそうではないらしい、「Suno」という音楽生成AIで作られた曲らしいということに気付きます。
そのときは「今は音楽もAIで自動生成できる時代になったのか……」と驚きを隠せませんでした。
ちょっと気になって調べてみると、どうも簡単な指示や操作だけで自分も曲が作れるようです。
ということで、さっそく登録。
無料プランだと生成できる回数が足りないのと、最新の v4.5 モデルが利用できないので、Pro Plan に課金。
※自動継続されないよう、課金後は自動更新をキャンセル。
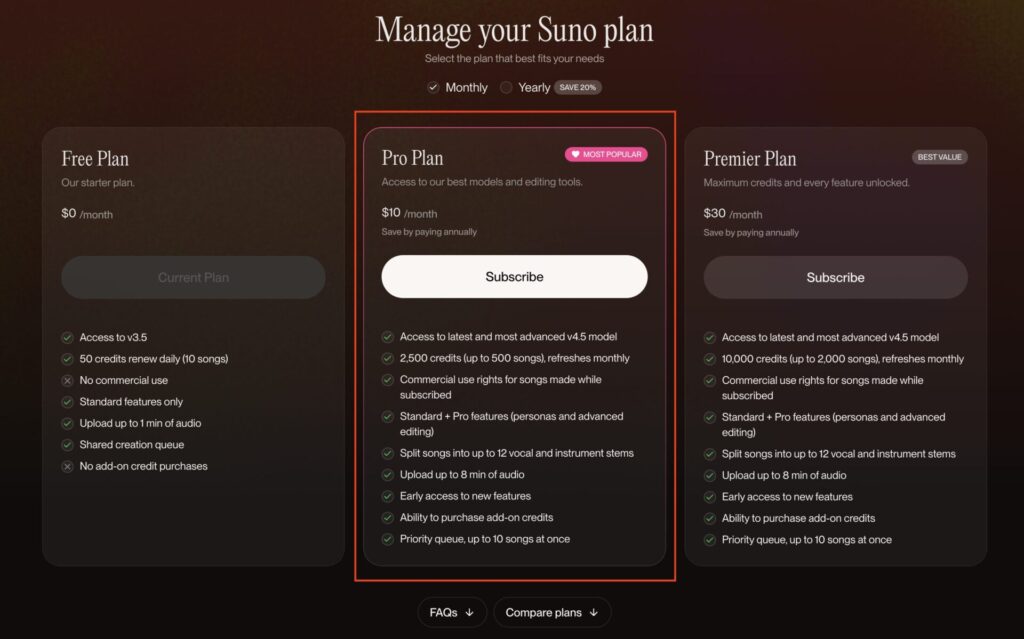
Pro Planのコスパは割といいのではないかと思います
次に思い出したのが、昔、大学の友人たちと作ったオリジナルノベルゲーム。
「そのゲームの世界観に合った歌詞を作って、AIに曲をつけてもらったら面白いかも」──そんな発想から、すべては動き出しました。
ちなみに、本筋から外れますが、Sunoについてもう少し詳しく知りたい方は、「あずきちゃんねる」というチャンネルの解説動画が見やすい&聞きやすくてオススメです!
アニメOP風動画の制作を決意した理由
ということで、まず最初は楽曲制作です。
Sunoには、楽曲の歌詞とその楽曲のスタイルを決めるStyle Descriptionというものをインプットとして入力する必要があります(歌詞は自動で生成してもらうことも可能です)。
ここで活用したのが、ChatGPTです。
ChatGPTは去年からPlusに課金して利用していたので、多少は使い慣れていました。
僕は、ChatGPT内でプロジェクト(複数のチャットやファイルをまとめておけるフォルダのようなもの)を作成すると、そこにオリジナルノベルゲームのシナリオデータを投入しました。
作詞とStyle Description設定をChatGPTに任せようと考えたのです。
個人的には、作詞は昔自分でもやったことがあり、こうしてブログで文章を書いているくらい「ものを書く」ことは好きなのですが、まずはスピード重視でやってみようと考えました。
シナリオデータを読み込ませた状態でChatGPTに「この作品がアニメ化したと仮定して、オープニングテーマになるような曲をsunoで作りたいと考えています。歌詞やStyle Descriptionを考えてもらえますか」といった内容の依頼をかけます。
そして、出力された歌詞やStyle Descriptionの結果を確認しつつ、それを実際にSunoにインプットして楽曲生成をしていきます。
うーすけそうしてできあがった楽曲がこちらです!
https://suno.com/s/3Irme0mr4GxH7waG
こうして、楽曲を実際に生成AIを利用して制作できると、今度はそれを利用した別のコンテンツ制作にも挑戦したくなってきました。
YouTube上にも、生成AIだけで制作されたMV風動画が多数投稿されていたので、自分もがんばればできるのでは? と思ったこともありますね。
そう、ここで次のステップとして生成AIを利用した「アニメOP風動画制作」への意欲が湧いてきたのでした。
アニメOP風動画制作 Step.1 – 利用する生成AIサービスの選定
では、アニメOP風動画を作るために、どの動画生成AIを利用するか。
次に決めるのは、このポイントでしたが、ここに関してはそこまで悩みませんでした。
というのも、Sunoでの楽曲制作を始めた頃から、僕はYouTubeで生成AI関連の動画を貪るように観るようになった結果、「アニメ動画の生成には『Vidu』というサービスがいいらしい」という情報を得ていたためです。
実際に、無料で使用できる範囲内でいくつかのアニメ動画を作成してみたところ、期待したものに近い動画が生成されたため、Viduは十分使えそうだという手応えを感じました。
Viduに興味を持った方は、「Vidu」というキーワードでYouTube動画を検索すれば結構いろんな方の解説動画が上がっているので、観てみてください。
個人的には「AI様の下僕」というチャンネルがわかりやすくてオススメです!
Viduの解説動画だけでなく、他にもいろんなAIの解説動画を出されていて、今でも視聴しているチャンネルです。
ただ、考えるべきポイントはもうひとつありました。
Vidu含む動画生成AIでは、「Text to Video」と呼ばれる「プロンプト情報のみをもとに動画を生成する」機能だけでなく、「Image to Video」つまり「画像をもとに動画を生成する」機能があります。
そして、生成される動画のクオリティは「事前に作成した画像をもとに『Image to Video』で動画を生成する方が高いらしい」という情報も得ていました。
つまり、次に決める必要があったのは「Viduにインプットとして入力する画像をどうやって用意するか」という点です。
候補には「ChatGPT」と「Midjourney」の2つがあり、その当時はそれぞれに以下のようなメリット・デメリットがあると考えていました。
| メリット | デメリット | |
| ChatGPT | ・すでにPlusに課金して利用しているので、追加の課金は必要なし(生成できる画像に上限がない状態となっている)。 ・チャットのやりとりで自然に画像生成や修正の指示を出すことができる。 | 特になし(と考えていた)。 |
| Midjourney | ・高品質な画像を生成可能(と評判)。 | ・無料プランがないため、生成を試してみることができない(課金が必要となる)。 |
当時の認識では、ChatGPTを利用することのデメリット(ChatGPTでは力不足である点)は特にないのではないかと考えていたんですよね。
ということで、まずはChatGPTでこちらが期待するクオリティの画像を生成することができるかを試してみることにしました。
ゲーム制作時に利用した立ち絵のイラストデータをChatGPTに渡しつつ、こちらが出した指示に従ってそのキャラクターを描くよう指示を出してみました。
しかし、結果はイマイチ……。
何となくそれっぽい画像は生成されるのですが、服のデザインや髪型で微妙にオリジナルと違う箇所が出てきて、しかもそこを修正するように指示をしても一向に修正されない、といったことが頻発します。
それに、イラストのタッチもオリジナルのものと同じではなく、ChatGPTのクセみたいなものが出て変にデフォルメされたものになってしまうのです。
いろんな構図や三面図の作成なども試してみましたが、どうがんばってもこちらが期待したようなクオリティの画像は生成されず、ChatGPTではViduへのインプットに使える画像生成は厳しいと判断しました。
僕のプロンプトの質が悪かったという問題ではないと思っているのですが、ChatGPTで「インプットとして提示した画像を忠実に再現しつつ新しい構図の画像を生成する」ためのノウハウを持っている方がもしいれば教えてほしいです……。
ということで、追加で課金が発生するのは止むなしと判断して、画像生成にはMidjourneyを利用することに決めました。
コスト的な観点で悩んだものの、一番安い Basic Plan だと十分な数の画像が生成できないかもしれないと思ったので、思い切って Standard Plan を契約しました。
だいたい4,500円/月くらいです。
好きでやっている趣味とは言え、さすがに躊躇はしましたね。
もちろん、自動継続されないように、課金後はすぐに自動更新をキャンセルしました。
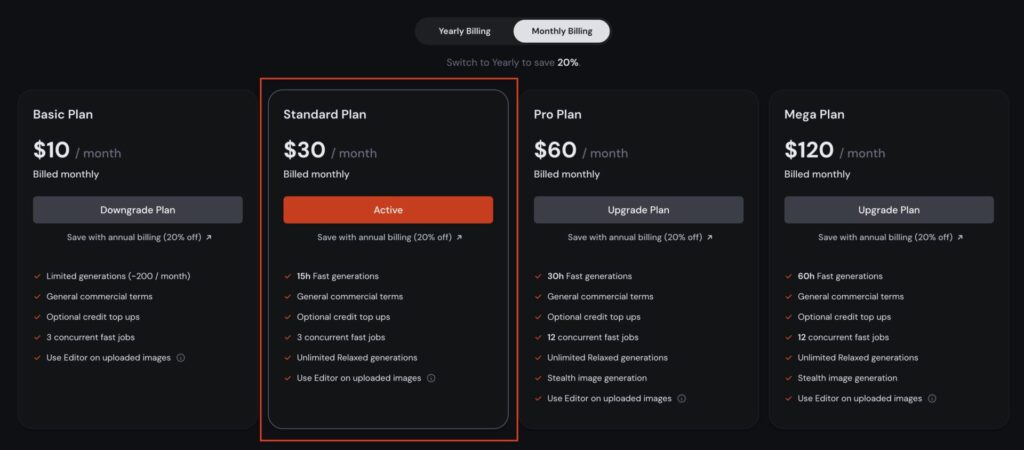
また、動画生成用のViduに関しても、一番安い Standard Plan だと Credits(生成を行う際に必要となるサービス内通貨のようなもの)が不足して動画が生成できなくなりそうだと感じていたので、Premium Plan にしました。
こちらは、だいたい5,250円/月くらいです。
これも、自動継続されないように、課金後はすぐに自動更新をキャンセルしました。
 うーすけ
うーすけ安くはない出費ですが、生成AI勉強のためとも思って割り切りました。
ということで、アニメOP風動画制作は以下の2つのサービスを軸にしていくことに決めました。
画像生成AI:Midjourney
動画生成AI:Vidu
アニメOP風動画制作 Step.2 – キャラクターデザイン作成
次に行ったのが、動画に登場させるキャラクターたちのキャラクターデザインの作成です。
オリジナルのゲームに登場させた立ち絵データはあるのですが、15年以上も前に制作したゲームなので、今回はリメイクという意味合いも兼ねて新しく作ろうと考えたのです。
Midjourney v7.0 から実装された Omni References 機能を利用してオリジナルの立ち絵データを参照させながら、特徴を描写した英語プロンプトを入力して、画像を生成していきます。
Omni References 機能関連で主に参考にさせていただいた動画は以下です。
このMidjourneyに入力する英語プロンプトを自分で考えていたらもうそれだけで力尽きてしまうので、ここでもAI活用ということで、ChatGPTを利用しました。
具体的には、入力された画像とテキスト情報をもとにMidjourney向けのプロンプトを自動生成して、それをワンクリックでコピーできる形で出力してくれるカスタム GPT を作成しました。
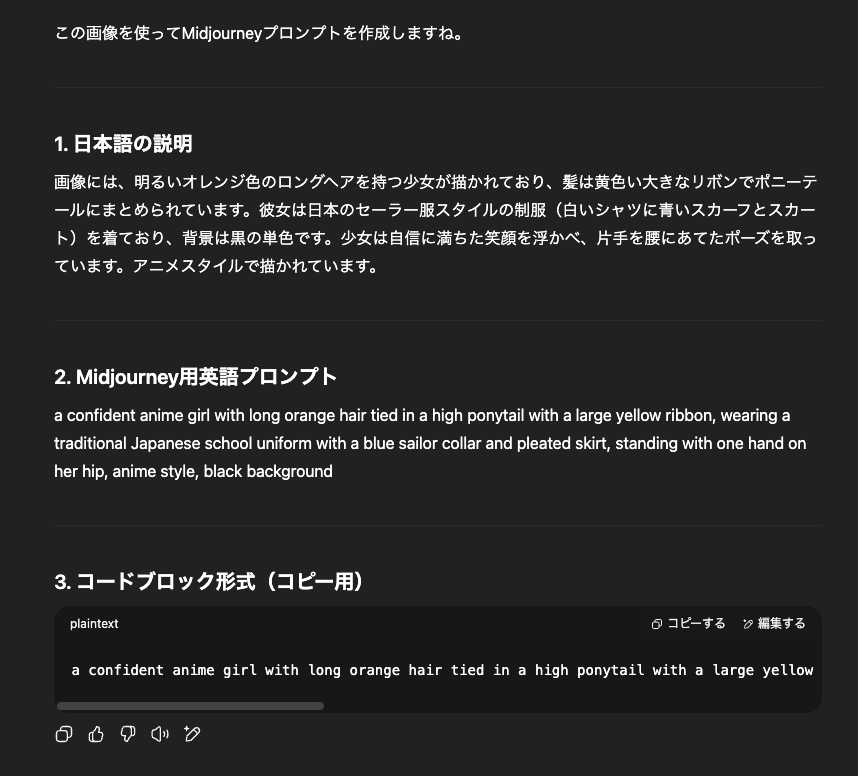
コードブロック形式のところに出力されているプロンプトを「コピーする」で一発コピーできるようにしています
このカスタム GPT のおかげでめちゃくちゃ時短できたと思います。
初回のプロンプト生成に役立つのはもちろんのこと、それを使ってMidjourneyで生成した画像が意図したものにならなかった場合も、チャットで修正指示を出すだけで新しいプロンプトを生成/出力してくれるんですよ。
ただ、実際のキャラクターデザイン生成はなかなか苦戦しましたね……。
指示に入れていないデザインを勝手に入れることもあれば、逆に指示している内容を守らないこともあったりで、思ったようにコントロールするのは難しかったですね。
画像生成AI系のYouTube動画だったりブログ記事だったりで、「生成はガチャ」とよく言われていた理由を、実際に身をもって知ることができました。
うーすけ生成を繰り返していくと、プロンプトに入れるべき情報が何となくわかってきます。
それでも、理想通りの画像が生成されるかは運要素が強いです。

Midjourneyの生成履歴より
アニメOP風動画制作 Step.3 – ストーリーボード作成
苦労しながらも何とか動画に登場させる可能性のあるキャラクターたちのデザインが完成したら、次はさっそく原画用の画像生成……ではなく、ストーリーボードの作成です。
僕の場合は iPad の「フリーボード」アプリを利用して、かなりざっくりな殴り書きレベルではありますが、動画全体の構成を書き出して整理しました。
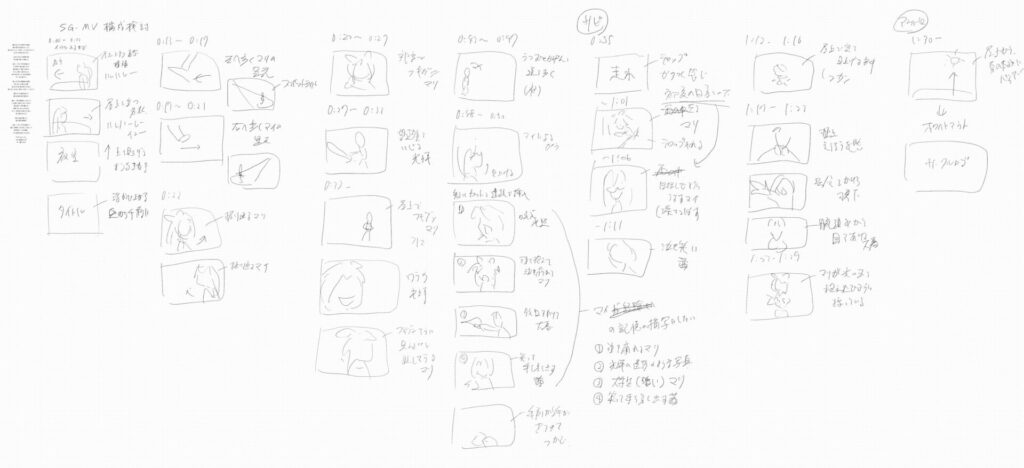
実際に動画制作を進めていくうちに「やっぱりここはこういう場面を挿し込みたい」とか「構想していた場面の描写が難しそうだ」とかいった理由で、最初に書いたストーリーボードの内容から離れることももちろんありました。
そういった場合はストーリーボードを修正します。
ただ、8割方は最初にストーリーボード作成を通じてイメージしたものに沿った動画になっていると思います。
わざわざ書き出さなくとも自分の頭の中で構成したイメージを忘れることは決してない、と断言できる人であれば不要だと思います。
ただ、多くの方はそうではないと思いますので、動画制作時に迷子にならないためにも、少し面倒に思っても最初にストーリーボードを整理しておくことをオススメします。
アニメOP風動画制作 Step.4 – 原画用画像生成&動画生成
ここまでできたら、いよいよ実際の動画制作に移っていきます。
Step.4-1 – 原画用画像生成
まずは、Viduで動画生成をする際のインプットとなる画像をMidjourneyで生成します。
ここでも、先ほどお話ししたカスタムGPTを活用しました。
Step.2 で作成したキャラクターデザインを渡した上で、どういう画像が欲しいかを依頼していきます。
例えば、Bメロ部分で黒髪長髪の少女が夜道を歩いているシーン用のプロンプトを生成したときの例が以下です。

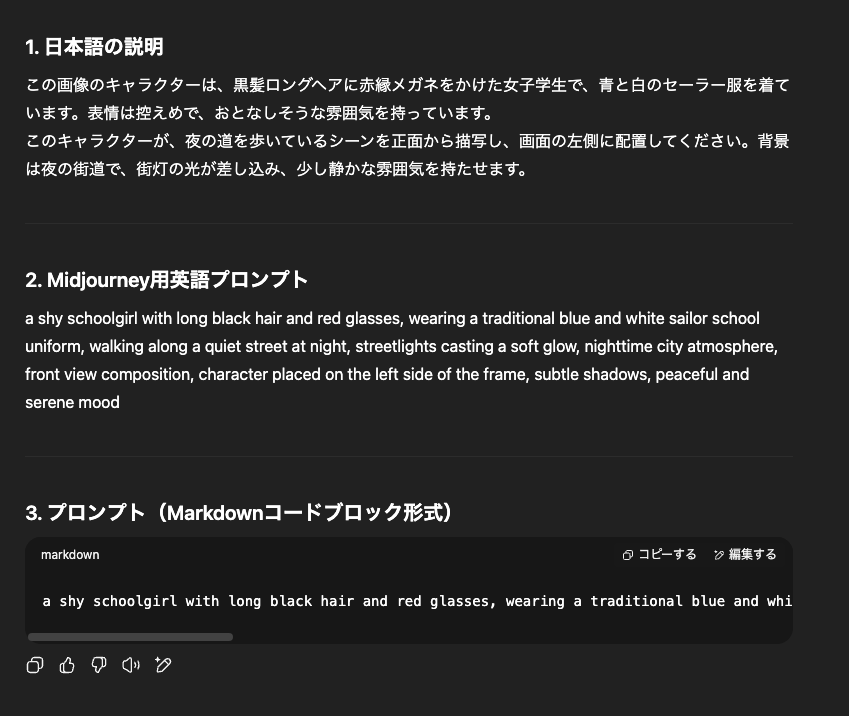
一発でイメージ通りの画像が生成できることはまずないので、このプロンプトを入れて生成された画像を見つつ、修正したい箇所を指示⇒プロンプト再出力⇒画像生成して確認、という流れを繰り返していきます。
この場面では以下の画像を使用することにしました。
※本当はロングスカートにしたかったのですが、どうやってもこの長さより長くなりませんでした……。

Step.4-2 – 動画生成
イメージに近い画像が生成できたら、今度はViduのImage to Video機能で動画を生成する際のプロンプトを考えます。
と言っても、ここでもやはりカスタムGPTを自作して活用します。
やることは、インプットとする画像を渡して、どういう場面を描きたいかを伝えるだけです。

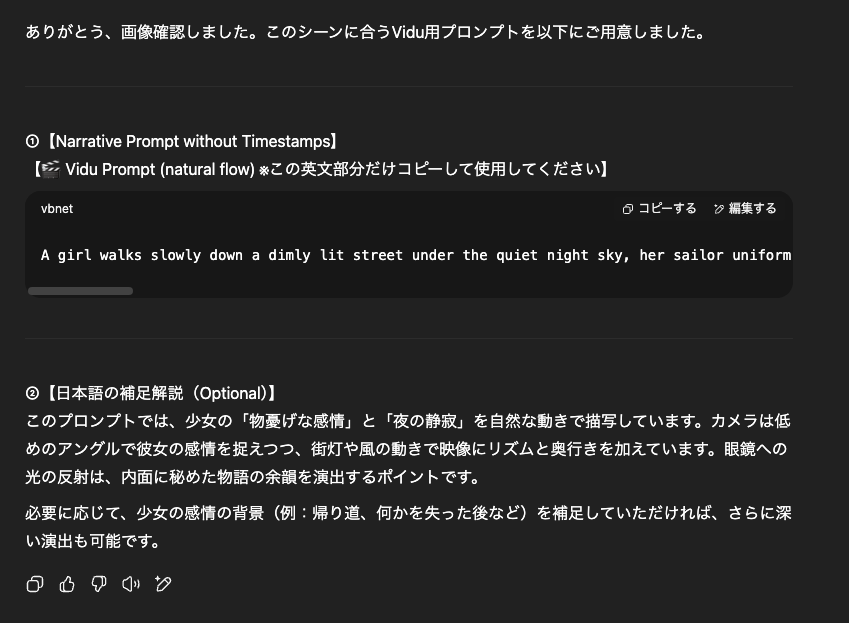
あとは画像生成のときと一緒ですね。
生成されたプロンプトを利用して動画を生成しつつ、イメージと違う箇所があればプロンプトの修正を依頼して、修正版プロンプトをもとにまた動画生成して確認する、といった流れです。
できた動画がこちらです。
(こぼれ話)「Vidu 2.0」を利用するか、「Vidu Q1」を利用するか
Viduで動画を生成する際、「Vidu 2.0」(以下、2.0)というモデルと最近リリースされたばかりの「Vidu Q1」(以下、Q1)というモデルを選択することができます。
※厳密には、2.0 より古いモデルも選択できますが、あえてそれを選択することはないと思いますので、ここでは割愛します。
簡単に言うと、「生成スピードが速い&消費コストも低い、けれども動画の質(解像度や動きの滑らかさ)はやや劣る」のが 2.0 で、「生成スピードは遅い&消費コストも高い(単純計算だと、2.0 の7.5倍の消費Credits)、けれども動画の質が高い」のが Q1 です。
最初は、コスト面の懸念から 2.0 しか使っていませんでした。
画質の粗さが少し気にはなるものの、よく動いてくれるし、十分視聴に耐えられるクオリティだと感じていたんですよね。
ただ、途中で「試しに1回だけ使ってみるか」と思って Q1 を使ってみたところ、そのあまりの画質の高さに震えました。
その衝撃が強すぎて、それまで 2.0 で作成していた動画も Q1 で再生成しようと心に決めたほどです。
それくらい、画質の面では 2.0 と Q1 の間には大きな壁があると感じました。
 うーすけ
うーすけQ1を一度使ったら、もう2.0の画質には戻れない……。
ただ、すべての面で Q1 の方が上かというとそうとも言えなくて、動きのダイナミックさに関しては、2.0 の方が上かなと感じました。
同じプロンプトを使っても、2.0 の方が動画に躍動感があり、その点では Q1 に物足りない印象を受けるところがありました。
それでもやはり段違いの画質の綺麗さには勝てず、僕の場合はほぼ全編 Q1 で生成した動画を使用しています。
アニメOP風動画制作 Step.5 – 動画編集
動画が生成できたら、いよいよそれらを繋ぎ合わせて1本の動画にする動画編集作業です。
今回、僕が使ったのは「Filmora」という動画編集ソフトです。

YouTube上に解説動画が数多く投稿されているし、動画編集時の操作も直感的にできるし、僕は結構気に入っています。
年額のサブスクに登録するか、買い切り版と呼ばれる永続ライセンス(※)を買うかの2択がありますが、僕は年額ライセンス(アドバンス年間プラン)にしました。
これもまた自動継続されないように、自動更新をキャンセルしました。
(※)永続ライセンスと言っても、「バージョンアップは別」らしく、利用しているバージョンより新しいものが出ると、またそこで(通常価格より安いとは言え)バージョンアップ費用がかかるらしいです。
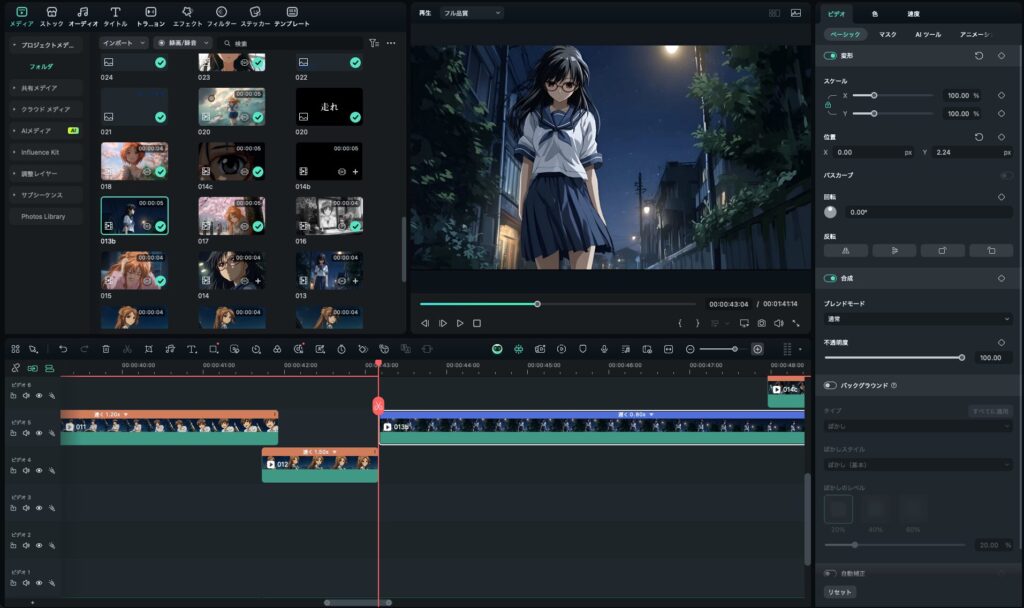
Step.4 と Step.5 という形で分けてはいますが、実際には並行して作業を進めました。
動画が生成できたら、その都度タイムラインにその動画素材を入れて流れを確認しながら編集して、次のカットの動画を生成する、といった感じですね。
 うーすけ
うーすけ少しずつ形になっていくのが目に見えて、この動画制作ステップに入ってからはますます意欲が増して、作業スピードが上がりました!
楽曲に乗せてキャラクターたちが動く姿を観ると、やはり興奮しましたね。
Bメロの最後からサビに入る箇所で、曲に合わせて場面が素早く入れ替わる演出を入れているのですが、特にそこがお気に入りです。
素人なので、ただ素材を繋ぎ合わせただけのような動画にはなってしまってはいるのですが、そこの演出だけはしっかり自分自身のクリエイティブ要素を入れることができたと感じています。
動画の完成
Step.4 の工程に入ってから約10日で、1分半のアニメOP風動画が完成しました。
個人的にはもっと時間がかかると思っていたので、想像以上に早く完成させることができて少し驚いています。
最後に改めて、完成した動画を貼っておきます。
ただ、できあがった直後は「これは傑作ができたんじゃないか!?」と興奮したものの、他の人がYouTubeに公開している動画生成AIを利用して制作されたアニメ動画を観たら、どれも自分よりクオリティが高いなと感じて、冷静になりました。
実際、今回の動画では自分のスキル不足で実現できなかったことがあります。
それは、1つの画面内に複数のキャラクターを入れて同時に動かす、ということです。
MidjourneyのOmni References機能を使うことによって、一貫性を保ちつつ1人のキャラクターを描くことは比較的簡単にできるのですが、複数のキャラクターを1つの画面に描くのが難しかったです。
複数のキャラクターデザインを1枚にまとめた画像を用意しておいて、それを参照させつつ、プロンプトで各キャラクターの詳細を説明するようにすればうまく生成できるんじゃないかと思ったのですが、なかなか上手くいかず……。
1人のキャラクターはうまく描けてももう1人のキャラクターが崩れたり、2人のキャラクターが混ざってしまったり……。
なので、動画を観てもらうとわかるのですが、1画面には1人のキャラクターしか出てきてないんですよね。
次はそのあたりも改善できるようにがんばりたいです。
うーすけいやー、まだまだ自分のレベルは低い……。
それでも、まったくのゼロから短いとは言え1本の動画を作り上げることができて、YouTube上で世界に発信できたことは自分の中で少し自信になりました。
さいごに
今回、いろいろと調べながら、そして実際に手を動かしながら、オリジナルのアニメOP風動画を制作できたので、その経験を無駄にしないように、また新たな動画制作に取り組みたいですね。
次は、今回作成した楽曲のフルバージョンを利用した実写ミュージックビデオを作成してみようかな、そうすると今度はリップシンクがキーになってくるので、そこに強い動画生成AIを調べるところからかな、なんてことを考えたりしています。
さて、では最後に、生成AIを利用した動画制作に興味がある方向けのメッセージを。
今回の記事の冒頭にも書いたとおり、生成AIを利用した動画制作は、決して簡単ではありません。
それなりに勉強したり、自分で触って試行錯誤したり、と時間はかかります。
僕の場合、この動画を制作している間、自分が自由に使える時間のほぼすべてをここに集中させました。
週末の夜なんかは、毎回朝方4時過ぎまで作業していましたしね。
それに、サービスを利用するにも無料でできる範囲はたかが知れているので、ある程度の課金は必要になってくるでしょう。
時間だけでなくお金もかかるということです。
「生成AIを使えば、時間的な意味でも金銭的な意味でも簡単に動画が作れる」と思っている人がもしいたら、それは完全に認識誤りなので、恐らく実際に動画制作に取り組んだとしても続かないと思います。
うーすけさすがにそんなに甘くはない……。
ただ、簡単ではありませんが、決して難しいということもありません。
ここまで説明してきたように、その気になってがんばれば誰でも僕のようにゼロ知識からでもそれなりのクオリティの動画を作ることができると思います。
今回の動画制作を通じて、やる気と覚悟さえあれば、自分だけでは作り得なかった作品を生成AIの助けを借りて作ることができるようになる時代がもう来ていると感じました。
今回の記事が、これから動画制作に挑戦したい人の背中を押せる内容になっていれば幸いです。
うーすけ興味があるなら、まず始めてみましょう!
コメント